Overview¶
RaSC is a free and open source middleware, developed by the Information Analysis Laboratory at the National Institute of Information and Communications Technology (NICT). RaSC facilitates high-speed and highly parallelized execution of user programs.
RaSC has been developed to apply user programs such as morphological analyzers and dependency parsers to a huge number of Web pages. To this end, RaSC runs various types of user programs and connects them across distributed computation nodes. A typical use of RaSC is to process multiple inputs in a file or in stream using multiple process instances of the user program in parallel with multi-core CPUs and/or many computation nodes. Although RaSC is originally designed for natural language processing (NLP), RaSC can work with various user programs, not limited to NLP programs. As long as the programs receive inputs from standard input or from a file, and output the result to standard output or to a file, they can be executed in a distributed manner on RaSC with slight changes in most cases.
The process instances of user programs running on RaSC will reside on memory once they started. For this reason, even programs that need a long time to start for any reason such as loading a large file — for example, NLP programs that load a dictionary file — can efficiently run. In addition, user programs on remote computer can be easily used through a network. When a number of inputs are given, the inputs can be distributed to multiple computers. The user programs can be easily connected through stream communication like a UNIX pipe, and they are executed in parallel without making users conscious of it.
A user program running on RaSC is accessible as a server through streaming network communication. This server is called a RaSC service. The RaSC service can be easily used from command lines or from various programing languages such as Java, Perl, Ruby, and Python. Thus RaSC can also be easily connected to other programs through various ways such as a pipe.
Architecture of RaSC service¶
Figure 1 shows the architecture of a RaSC service. In the default settings, a RaSC service will create a new process instance of the user program when receiving a request.
Even when the processing for the request completes, the process instance will not be terminated to be reused for processing following requests. For this reason, you can immediately process requests even when the user program needs a long-time startup.
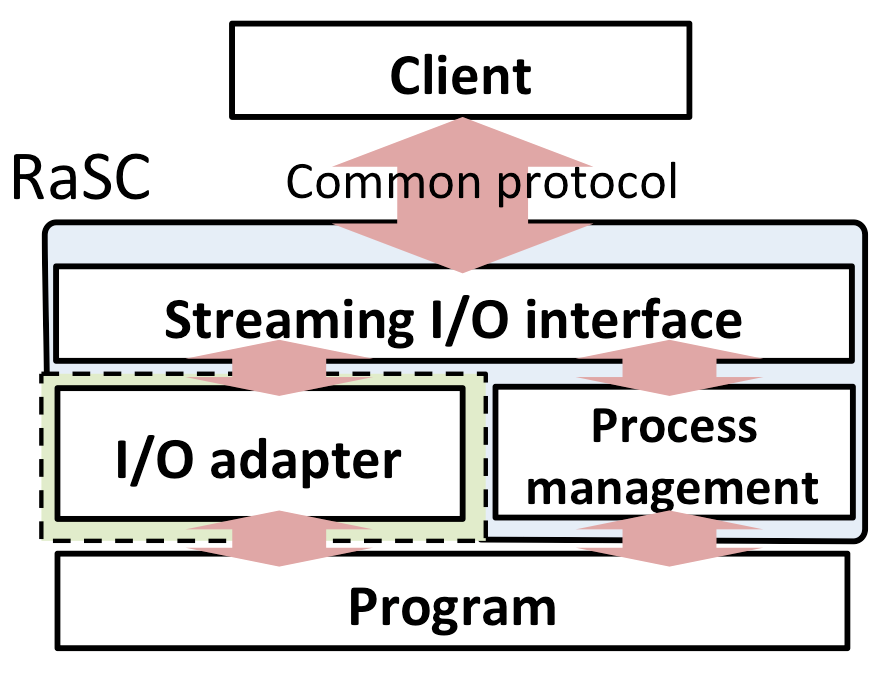
Figure 1: Architecture of RaSC service
When the RaSC service receives a new request while all the process instances are busy, it will create a new process instance until the number of process instances reaches its predefined limit. When the number of process instances reaches the limit, the request will be put in a queue. After any process instance is freed, the requests in the queue will be executed sequentially in a certain order. If any process instance is not freed within a certain time period, an error will be returned.
Programs that can run with RaSC¶
The user programs must meet the following conditions to run on RaSC:
- Perform I/O through standard input and output
- Output results for one input when it is given, and wait for the next output without termination.
- Output an explicit termination character(s) for one output.
Some programs such as the morphological analysis program MeCab and dependency parser J.DepP meet the above conditions, which means that they receive one input with a linefeed as a termination character, and that they output a result with termination character string EOS, and after that wait for the next input.
The programs that do not meet these conditions must be modified to run on RaSC. If the source codes is available, it is not very difficult to modify them in most cases, and for some programs such as SVM Perf and CRF++, you can download patches from this site.
Parallelize and distribute large-scale analysis¶
RaSC provides a mechanism to execute user programs in parallel that have been distributed on multiple computers.
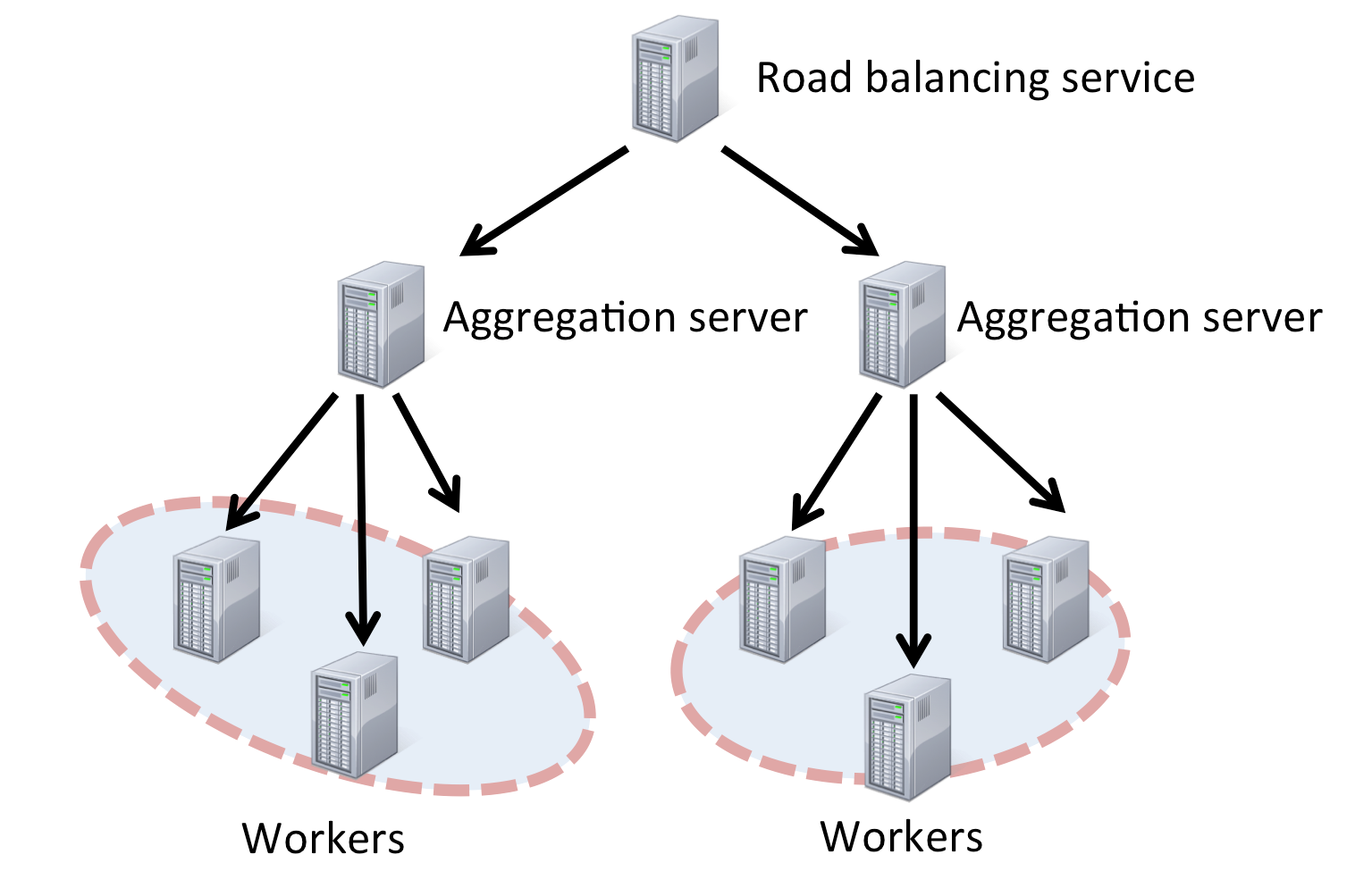
Figure 2: Distributed, Parallel Execution of RaSC Service
Figure 2 shows a configuration to process huge data by dividing the data into smaller different units on different computers. The aggregation server calls worker nodes in parallel that process the unit, and aggregates the results. The aggregation server can also apply post-processing such as filtering and ranking to them.
In addition, the load balancing service allows users to define multiple sets of aggregation servers and workers to distribute loads by a round robin, etc.