関係知識を利用する全文検索システム QE4Solr Version1.0
目次
関係知識を利用する全文検索システム QE4Solr とは、異表記辞書や同義語辞書、単語間意味的関係知識等を用いてクエリを自動拡張する全文検索システムです。大量の異表記、同義語、意味的関係知識によりクエリ拡張することで、検索漏れの防止や、意外だが有用な情報の発見が期待できます。また、索引付けと検索の並列処理が可能で、Webアーカイブ等の大規模な文書データも効率的に処理できます。異表記辞書や同義語辞書、単語間意味的関係知識等は、高度言語情報融合フォーラム ALAGIN を通して入手可能です。以下に挙げるような知識を得ることができます。
- 異表記、同義語の例:(ギョウザ,ギョーザ), (バイオリン,ヴァイオリン), (情報漏洩,情報漏えい),
(情報漏洩,情報流出), (ろうきん,労働金庫), (白滝,糸こんにゃく), (キャリアサポート,就職支援)
- 意味的関係知識の例:
- (原因 - 結果)関係の例:(高脂血症 - 動脈硬化), (動脈硬化 - 脳梗塞), (連鎖球菌 -
化膿性関節炎), (トラウマ - PTSD), (断層 - 直下型地震)
- (トラブル - 予防策)関係の例:(情報漏えい - 暗号化ソフトウェア), (床ずれ - エアマット),
(鳥害 - 防鳥ネット), (壁内結露 - 羊毛断熱材), (尿モレ- 立体ギャザー)
本システムは、索引付けと検索のコアエンジンとして Apache Solr を使用しています。

Apache SolrにはSynonymFilterという機能があり、これを利用することでQE4Solrの自動クエリ拡張機能の一部と同じような効果が期待できます。しかし、QE4Solrと違い、拡張の結果得られた語のスコア(あるいは、拡張で得られた語を検索の際どの程度重視するか)をユーザが自由に調整することはできません。例えば、ユーザが入力した元のクエリ「情報漏洩」のスコアを1として、自動拡張の結果得られた語「暗号化ソフトウェア」のスコアを0.5にする、というようなことはApache Solrには不可能で、QE4Solrにしかできません。またQE4Solrでは、自動クエリ拡張にどの辞書を使用するかを、検索を実行するたびに、ユーザが選択できるようになっています。これもApache Solrにはない機能です。詳しくは「検索の事前準備」で述べます。
- 2013-05-01 関係知識を利用する全文検索システムv1.0 リリース
本システムの動作環境は次のとおりです。
- OS: Windows(XP以上)、Linux
- RAM: 2GB以上推奨
下記環境で動作確認済
Windows XP SP3 Intel(R) Pentium(R) 4 CPU 3.40GHz、1.98 GB RAM
Linux CentOS release 5.4,kernel version 2.6.30.10 Intel(R) Xeon(R) CPU 2.40GHz、48 GB RAM
※本ページの説明では、Linuxを用います(Windowsを用いた説明はこちら)。
本システムを実行するには以下のツールが必要です。
- jdk1.5以上
→ ダウンロード ※URLは変更になる場合があります
- prototype.js 1.6.0.3以上
→ ダウンロード ※URLは変更になる場合があります
- Solr(Solr 1.4.2devで動作確認済)
※Solr 3.x以上には未対応です
- Sen(Sen1.2.2.1で動作確認済)
※Senの解析用辞書の構築にはPerl、Antが必要です
なお、本ページの説明ではサーブレットコンテナにSolr同梱のJettyを用います。
以下にSolr、Senの具体的なインストール方法を記載します。
Solrのインストール
- 必要なツールの準備
この作業にはSubversionとAntのツールが必要となります。
Ant (apache-ant-1.8.2で動作確認済)※URLは変更になる場合があります
-
Solr1.4.2devのチェックアウト
SolrのSVNリポジトリから、Solr1.4.2devのソースコードを取得します。
> cd /home/user_name
> svn co https://svn.apache.org/repos/asf/lucene/solr/branches/branch-1.4
- ビルド
Solr1.4.2devをビルドします。成功すると
branch-1.4/example/webapps/solr.war ができます。
> cd branch-1.4
> ant example
なお、インターネットへの接続をプロキシサーバ経由で行なっている場合は、
branch-1.4/contrib/clustering/build.xml
にプロキシの設定(下記の赤字の部分)を加えた後、ビルドを行なってください。
<project name="solr-clustering" default="build">
<property name="solr-path" value="../.."/>
<setproxy proxyhost="[ホスト名]" proxyport="[ポート番号]" />
<import file="../../common-build.xml"/>
- ディレクトリ名のリネーム
ディレクトリ名を変更します。以降の説明では、Solrがインストールされたディレクトリの場所を$SOLRと記載します。
> cd ..
> mv branch-1.4 solr
Senのインストール
- 必要なツールの準備
この作業にはSubversionのツールとAntが必要となります。
Ant (apache-ant-1.8.2で動作確認済)※URLは変更になる場合があります
-
Senのチェックアウト
SenのSVNリポジトリから、ソースコードを取得します。
まず、Senのソースコードをチェックアウトします。
> cd /home/user_name
> svn co https://svn.java.net/svn/sen~svn/tags/SEN_1_2_2_1/sen
> mv sen sen-1.2.2.1
以降の説明では、Senがインストールされたディレクトリ(/home/user_name/sen-1.2.2.1)を$SEN_HOMEと記載します。
- build.xmlの設定
$SEN_HOME/build.xml を変更します。具体的には、下のようにcppを実行する部分をコメントアウトします。
<!--
<exec executable="cpp" output="${src.dir}/net/java/sen/util/DoubleArrayTrie.java" >
<arg line="-P ${src.dir}/net/java/sen/util/DoubleArrayTrie.cpp"/>
</exec>
-->
- Senのビルド
$SEN_HOME に移動し、antを実行します。
> cd sen-1.2.2.1
> ant
Sen用辞書(IPA辞書)の構築
Sen用辞書(IPA辞書)の構築は以下の手順で行ないます。
- 辞書の構築に必要なツールの準備
辞書の構築にはPerl、Antが必要となります。
Perl (Perl 5.8.8で動作確認済)
Ant (apache-ant-1.8.2で動作確認済)
※URLは変更になる場合があります
- 辞書の文字コード設定
$SEN_HOME下にある次の3ファイルを修正します。
| $SEN_HOME/conf/sen.xml |
→ charsetをutf-8に変更 |
| $SEN_HOME/conf/sen-processor.xml |
→ charsetをutf-8に変更 |
| $SEN_HOME/dic/dictionary.properties |
→ sen.charsetをUTF-8に変更 |
- CLASSPATH設定
以下のコマンドを実行します。コマンド中の $SEN_HOME
はSenをインストールしたディレクトリに置き換えてください。
> export CLASSPATH=$CLASSPATH:$SEN_HOME/lib/sen.jar:$SEN_HOME/lib/commons-logging.jar
- 辞書のインストール
$SEN_HOME/dic に移動し、antコマンドを実行します。
> cd $SEN_HOME/dic
> ant
※プロキシを経由して辞書をインストールする場合は、プロキシのホスト名とポート番号を指定してください。
コマンド: ant -Dproxy.host=[ホスト名] -Dproxy.port=[ポート番号]
下のパッケージをダウンロードしてください。
- 関係知識を利用する全文検索システム QE4Solr (2.2MB): (tar.gz) (zip)
関係知識を利用する全文検索システムパッケージには、次のものが含まれます。
- README (README, doc)
- 検索システム本体(QE4SolrApp.war)
- コマンドラインツール(QE4Scommand)
- インデックス作成制御プログラム(IndexingControl)
- プロパティファイル(QE4Solr.properties)
- Javaライブラリファイル(QE4Stools.jar)
- 辞書サンプル(sampleDic)
- 検索対象文書サンプル(search_target)
辞書サンプルには次のものが含まれます。
パッケージの展開は以下の手順で行ないます。
-
以下のコマンドを実行し、ダウンロードしたパッケージを展開します。展開すると、QE4Solrディレクトリができます。
※/home/user_name/workにパッケージをダウンロードした場合
> cd /home/user_name/work
> tar xfz QE4Solr.tar.gz
または
> unzip QE4Solr.zip
-
インデックス作成制御プログラム(IndexingControl)を/home/user_nameに移動します。辞書サンプル(sampleDic)もディレクトリごと/home/user_nameに移動します。
> mv QE4Solr/IndexingControl /home/user_name
> mv QE4Solr/sampleDic /home/user_name
異表記辞書、関係辞書の配置図は次のとおりです。全てsampleDicディレクトリに格納します。
/home/user_name/sampleDic
|
+--- allographic-pairs-v1.utf8.tsv.txt # 異表記辞書
|
+--- all-caus.cln.dfflt.sort.nomrp_0.5.txt # 関係辞書(因果)
|
+--- all-prev.cln.dfflt.sort.nomrp_0.5.txt # 関係辞書(予防)
|
+--- all-mate.cln.dfflt.sort.nomrp_0.5.txt # 関係辞書(材料)
-
検索システム本体(QE4SolrApp.war)と検索対象文書サンプル(search_target)を$SOLR/example/webappsに移動し、Solrを起動します。この操作により検索システム本体が$SOLR/example/workに展開されます。
> mv QE4Solr/search_target $SOLR/example/webapps
> mv QE4Solr/QE4SolrApp.war $SOLR/example/webapps
※Solrの起動方法は、下の「Solrの起動・停止」を参照してください。
※Solrの起動・停止
$SOLR/exampleにあるstart.jarを実行するとSolrが起動します。Solrを停止する場合は、実行中のstart.jarをCtrl+Cで停止します。
> cd $SOLR/example
> java -jar start.jar
本システムの検索処理に必要なデータは次のとおりです。
- 検索対象文書
(文字コード:UTF-8 改行コード:LF)
- 辞書(異表記、関係)
(文字コード:UTF-8 改行コード:LF)
次に、検索対象文書と辞書のそれぞれの形式と項目について説明します。
- 検索対象文書
-
本システムは、検索対象文書として以下2種類の形式を受け付けます。
検索対象文書に必要な項目は次の4項目です。
各形式の具体的なフォーマットを次に示します。
【XMLファイルのフォーマット】
1ファイルに1つのadd要素を記述します。add要素の子要素にdoc要素を記述します。なお、doc要素はadd要素に複数記述できます。
doc要素の子要素としてfield要素を記述し、その値に必要な項目を加えます。具体的には、IDはname属性値を"id"とするfield要素に記述します。同様に、タイトルはname属性値を"title"とするfield要素に記載し、内容はname属性値を"body"とするfield要素に記載し、URLはname属性値を"siteurl"とするfield要素に記載します。
<?xml version="1.0" encoding="UTF-8" ?>
<add>
<doc>
<field name="id">ID(doc要素を一意に識別する整数)</field>
<field name="title">タイトル</field>
<field name="body">内容</field>
<field name="siteurl">URL</field>
</doc>
<doc>
・
・※docは複数指定可能
・
</doc>
</add>
なお、XMLフォーマットでは1つのdoc要素内にURLを複数指定することができます。その場合、対応するアンカーテキストも指定する必要があります。
具体的には、URLはname属性値を"siteurl[数字]"とするfield要素に記載します。アンカーテキストは、name属性値を"anchor[数字]"とするfield要素に記載します。[数字]は、URL、アンカーテキストの数に応じて1から順に2,3,4,,,と指定します。URLのアンカーテキストは、[数字]が同じアンカーテキストになります。
例えば、GoogleとYahoo!のリンクを指定する場合、doc要素に次のfield要素を加えます。
<field name="siteurl1">http://www.google.co.jp/</field>
<field name="anchor1">Google</field>
<field name="siteurl2">http://www.yahoo.co.jp/</field>
<field name="anchor2">Yahoo</field>
【テキストファイルのフォーマット】
テキストファイルのデータをシステムは次のように認識します。
・ID…インデックス作成処理において付与される一意の整数値
・タイトル…テキストデータの一行目
・内容…二行目以降の全データ(一行目が50文字を超える場合は、51文字以降を含む)
・URL…テキストファイルの場所(ファイルへのパス)
- 辞書(異表記、関係)
-
各辞書の記載項目は次のとおりです。具体的には、辞書サンプルの記載を参考にしてください。なお、辞書の作成にはALAGINにおいて公開中の辞書や辞書構築ツールをご利用いただけます。
- 異表記辞書
-
異表記辞書の形式は、次の項目を半角カンマ区切りで記載したテキストファイルです。スコアには0~1の値を指定してください。
語1,・・,語N,スコア
語1、・・、語Nが異表記関係にあることを示します。いずれかの語をキーとして他の語が異表記語として得られます。
スコアと異表記重みを掛け合わした値が各異表記語の重みになります(異表記重みについては「辞書の設定について」を参照)。
下に辞書サンプルの一部を示します。
一括払,一括払い,0.5
シブイ,シブい,0.5
外部スピーカ,外部スピーカー,0.5
記事カテゴリ,記事カテゴリー,0.5
予備バッテリ,予備バッテリー,0.5
- 関係辞書
-
関係辞書は、何らかの意味的関係にある単語ペアを列挙した辞書です。意味的関係とは、例えば「原因-結果」関係や「トラブル-予防策」関係などです。「原因-結果」関係辞書なら「連鎖球菌-化膿性関節炎」「断層-直下型地震」などが、「トラブル-予防策」関係辞書なら「情報漏えい-暗号化ソフトウェア」「尿モレ-立体ギャザー」などの単語ペアが収録されます。各単語ペアに与えられているスコアは、その単語ペアが当該関係にあることがどの程度正しそうかを表します。
関係辞書の形式は、次の項目を半角カンマ区切りで記載したテキストファイルです。スコアには0~1の値を指定してください。
語1,語2,スコア
各関係ペアのスコアと順方向重みを掛け合わした値が各関係ペアの順方向の重みになります。同様に、各関係ペアのスコアと逆方向重みを掛け合わした値は、各関係ペアの逆方向の重みになります(順方向重み、逆方向重みについては「辞書の設定について」を参照)。
下に辞書サンプルの一部を示します。語1と語2の因果関係(語1が語2を引き起こす場合があること)を示しています。
高脂血症,アルツハイマー病,0.5
スナック菓子,生活習慣病,0.5
後遺症,糖尿病,0.5
ノロウイルス,飛沫感染,0.5
おでき,痒み,0.5
検索対象文書から検索用のインデックスを作成します。インデックス作成時には、辞書(異表記、関係)を参照します。
インデックスの作成には、インデックス作成制御プログラム(IndexingControl)と検索システム本体(QE4SolrApp.war)を用います。インデックス作成制御プログラムを起動すると、検索システムのインデックス処理が開始します。具体的には以下の手順で行ないます。
- Solrの設定
インストールしたSolrの設定を本システム用に変更します。具体的な変更点は次の3点です。
■ログディレクトリの作成
ログファイルを出力するディレクトリを作成します。ここにはインデックス作成時のログ(log.txt)と検索時のログ(QE4Solr.log)が出力されます。
> mkdir $SOLR/example/solr/data/log
■スキーマの設定
$SOLR/example/solr/conf/schema.xml の<fields>要素と<types>要素の内容を変更します。
- <fields>要素
-
schema.xmlに記載されている、title、description、keywordsフィールドの設定を変更します(赤字部分が変更箇所)。
<field name="title" type="text_sen" indexed="true" stored="true" multiValued="false"/>
<field name="description" type="string" indexed="false" stored="true" multiValued="false"/>
<field name="keywords" type="string" indexed="false" stored="true" multiValued="false"/>
以下の<field>要素を新たに加えます。
<field name="title_cjk" type="text_cjk" indexed="true" stored="true" multiValued="false"/>
<field name="body" type="text_sen" indexed="true" stored="true" multiValued="false" termVectors="true"/>
<field name="body_cjk" type="text_cjk" indexed="true" stored="true" multiValued="false" termVectors="true"/>
<dynamicField name="siteurl*" type="string" indexed="false" stored="true" multiValued="false"/>
<dynamicField name="anchor*" type="string" indexed="false" stored="true" multiValued="false"/>
<field name="PrepareRelation" type="string" indexed="false" stored="true" multiValued="false"/>
<field name="PrepareClass" type="string" indexed="false" stored="true" multiValued="false"/>
- <types>要素
-
Solrにトークナイザ(CJKTokenizer、SenTokenizer)を設定します。次のコードを<types>要素に加えます。なお、SenTokenizerのconfigFileとBasicStringに設定する値について以下に説明します。
-
configFile・・・Senのconfディレクトリにあるsen.xmlを指定します。
-
BasicString・・・形態素の基本形(原形)を使うか否かを指定します。1を設定すると原形を、0を設定すると表層形を用います。例えば、「書かない」という文字列は、原形を用いると指定した場合「書く ない」と分割され、表層形を用いると指定した場合「書か ない」と分割されます。
<fieldType name="text_cjk" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.CJKTokenizerFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_sen" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="qe4stools.analysis.SenTokenizerFactory" configFile="[$SEN_HOME/conf/sen.xml]" BasicString="1"/>
</analyzer>
</fieldType>
- Javaライブラリの設置
Javaライブラリをlibディレクトリに設置します。
- Solr用libディレクトリ作成
-
$SOLR/example/solrにlibディレクトリを作成します。
- jarファイルの配置
-
パッケージに含まれるJavaライブラリ(QE4Stools.jar)を$SOLR/example/solr/libにコピーします。
> mkdir $SOLR/example/solr/lib
> cp -p QE4Solr/QE4Stools.jar $SOLR/example/solr/lib
$SEN_HOME/libにあるsen.jarとcommons-logging.jarを$SOLR/example/libにコピーします。
> cp -p $SEN_HOME/lib/sen.jar $SOLR/example/lib
> cp -p $SEN_HOME/lib/commons-logging.jar $SOLR/example/lib
$SOLR/example/work/Jetty_0_0_0_0_8983_solr.war__solr__[******]/webapp/WEB-INF/libにあるjarファイルを$SOLR/example/work/Jetty_0_0_0_0_8983_QE4SolrApp.war__QE4SolrApp__[******]/webapp/WEB-INF/libにコピーします。 (*は半角英数字)
> cp -p $SOLR/example/work/Jetty_0_0_0_0_8983_solr.war__solr__[******]/webapp/WEB-INF/lib/*
$SOLR/example/work/Jetty_0_0_0_0_8983_QE4SolrApp.war__QE4SolrApp__[******]/webapp/WEB-INF/lib
- プロパティファイルの設定
インデックス作成制御プログラム(IndexingControl)と検索システムが読み込むプロパティファイル(QE4Solr.properties)を作成します。システムプロパティおよび辞書に関する以下の項目を指定してください。なお、ファイルやディレクトリを指定する際は、必ず絶対パスで指定してください。
- システムプロパティ設定
-
以下の項目を指定します。それ以外の項目はそのままで構いません。
-
SEARCH_TARGET_DATA
検索対象文書を格納するディレクトリを指定します。
-
ServerURLs
サーバのホスト名:ポート番号を指定します。
-
Solr_HOME
$SOLR/example/solrを指定します。
-
SEN_HOME
$SEN_HOMEを指定します。
-
Solr_URL
サーバのホスト名:ポート番号を指定します。
-
DO_PREPARE_RELATION
インデックス作成の際、関係辞書を用いて検索対象文書から関係データを抽出する処理(以降、この処理を「関係事前抽出」と記載します)の実施についてON、OFFのいずれかで指定します(初期値:ON)。
関係事前抽出処理では、文書中の語のうち検索語を除いた語に対して関係辞書を適用し、意味的関係を抽出します。この処理によって得た関係データは検索結果表示画面に表示されます。
なお、関係事前抽出処理を加えるとその分インデキシングの時間は若干遅くなります。
-
PREPARE_RELATION_COUNT
関係事前抽出において、1文書から抽出するデータ数を指定します(初期値:20)。
-
GET_CLASS_RELATION_FIELD
関係事前抽出処理を行なうフィールド名を指定します。ここで指定されたフィールドの値から関係データが抽出されます。なお、半角カンマ区切りで複数のフィールドが指定可能です。
-
EMBEDDED_SOLR
インデックスデータの登録方法をON、OFFのいずれかで指定します(初期値:ON)。ONにするとインデックスファイルを直接操作し登録します。OFFにするとHTTP経由でデータの登録を行ないます。
-
COMMIT_PERIOD
インデックス作成時、登録したデータをコミットする周期を指定します(初期値:100000件)。
-
WebappDIR
サーバの公開ディレクトリを指定します。例えばJettyの場合、$SOLR/example/webappsを指定します。
以上の項目の記載例を次に示します。
SEARCH_TARGET_DATA=/home/user_name/solr/example/webapps/search_target
ServerURLs=localhost:8983
Solr_HOME=/home/user_name/solr/example/solr
SEN_HOME=/home/user_name/sen-1.2.2.1
Solr_URL=localhost:8983
DO_PREPARE_RELATION=ON
PREPARE_RELATION_COUNT=20
GET_CLASS_RELATION_FIELD=title,body
EMBEDDED_SOLR=ON
COMMIT_PERIOD=100000
WebappDIR=/home/user_name/solr/example/webapps
設定したシステム、ツールの配置図は次のとおりです。
/home/user_name
|
+--- solr(Solrをインストールしたディレクトリ)
| |
| +--- example
| |
| +--- solr(プロパティファイルでSolr_HOMEに指定するsolrディレクトリ)
| |
| +--- webapps
| |
| +--- search_target(検索対象文書を格納するディレクトリ)
|
+--- sen-1.2.2.1(Senをインストールしたディレクトリ)
|
+--- sampleDic(辞書を格納するディレクトリ)
- 辞書の設定
-
続いて辞書の設定例を示します。ここでは辞書サンプルの辞書を用います。
ユーザの入力した検索語の重みはデフォルトで1.0です。下記例の場合、異表記関係や因果関係により追加される語の重みを小さく(0.5)設定しています。また因果関係の逆方向重みを0にすることで、この知識を順方向にしか使わないよう指定しています。
異表記辞書設定(IHYOUKI):半角カンマ区切りで、[異表記名],[利用するファイル],[異表記重み] *1 を記載します
IHYOUKI=異表記関係,/home/user_name/sampleDic/allographic-pairs-v1.utf8.tsv.txt,0.5
関係辞書設定(RELATION):半角カンマ区切りで、[関係名],[利用するファイル名],[順方向重み] *2 ,[逆方向重み] *2 を記載します
RELATION=因果関係,/home/user_name/sampleDic/all-caus.cln.dfflt.sort.nomrp_0.5.txt,0.5,0
*1 異表記重みは、各異表記語の重みの算出に用います。0~1の値を指定します。
*2 順方向重みは、語1をキーにして得られた語2の重みの算出に用います。逆方向重みは、語2をキーにして得られた語1の重みの算出に用います。いずれも0~1の値を指定します。
- プロパティファイルの設置
1.で設定したプロパティファイルを下のディレクトリに移動します。
$SOLR/example/work/Jetty_0_0_0_0_8983_QE4SolrApp.war__QE4SolrApp__[******]/webapp/properties
(*は半角英数字)
- Solr再起動
Solrを再起動することでプロパティファイルの設定を読ませます。$SOLR/exampleに移動し、Solrを再起動してください。(起動・停止方法)
- インデックス作成制御プログラム起動
IndexingControlディレクトリにあるexec.shを起動します。
「プロパティファイルのパスを指定してください。」と表示されますので、3.で設置したパスを指定し、リターンキーを押します。
> /home/user_name/IndexingControl/exec.sh
「プロパティファイルのパスを指定してください。」と表示されるので、3.で設置したパスを入力してEnterを押す。
> $SOLR/example/work/Jetty_0_0_0_0_8983_QE4SolrApp.war__QE4SolrApp__[******]/webapp/properties/QE4Solr.properties
インデックス作成制御プログラムは、プロパティファイルの「ServerURLs」項目に指定されたサーバに対して、インデックス作成を行なうよう命令します。
処理が終わると、「すべての処理が終了しました。」というメッセージが表示され、処理を終了します。なお、インデックスデータは$SOLR/example/solr/data/indexディレクトリにできます。
検索システムの起動は、以下の手順で行ないます。
- プロパティファイルの設定
必要に応じて検索実行に関わる設定を変更します。以下の4項目が該当します。
# DISPLAY_RELATION_COUNT 事前抽出した関係知識の表示数
# (スコアの降順の上位「表示数」件表示)を指定します。
DISPLAY_RELATION_COUNT=5
# RELATION_COUNT クエリ拡張に用いる知識数(異表記知識と関係知識のそれぞれについて、
# スコア降順の上位「知識数」件を用いる)を指定します。
RELATION_COUNT=5
# SearchURLs サーバのホスト名:ポート番号を指定します。
# 複数のサーバを指定する場合は、ホスト名:ポート番号を半角カンマ区切りで記載します。
SearchURLs=localhost:8983
# SHOW_RELATION_LIST 事前抽出した(クラス|関係)知識を表示するか否かON、OFFのいずれかで指定します。
SHOW_RELATION_LIST=ON
- prototype.jsの配置
prototype.jsを次のディレクトリに設置します。
$SOLR/example/work/Jetty_0_0_0_0_8983_QE4SolrApp.war__QE4SolrApp__[******]/webapp/js
(*は半角英数字)
> cp -p prototype.js $SOLR/example/work/Jetty_0_0_0_0_8983_QE4SolrApp.war__QE4SolrApp__[******]/webapp/js
- Solr起動
$SOLR/exampleに移動し、Solrを起動します。既に起動している場合は一度停止し、改めて起動してください。(起動・停止方法)
本システムは、ウェブアプリケーションとして使用します。次のURLにアクセスすると、検索画面に移動します。
http://[Solrをインストールしたサーバのホスト名]:8983/QE4SolrApp/
以下、検索画面、検索設定画面、検索結果画面について説明します。
- 検索画面
-
「検索語」欄にキーワードを入力し検索ボタンを押すと検索処理が始まります。

- 検索設定画面
-
検索画面の「検索設定」リンクをクリックすると、検索設定画面が表示されます。
ここにはプロパティファイルで指定した知識が表示されますので、検索の際に使用する知識を指定します。
使用する知識にチェックを付け、登録ボタンを押下してください。画面上で行なったチェックの変更が登録されます。「検索画面へ」をクリックすると、検索画面に戻ります。

- 検索結果画面
-
検索結果画面には次の3項目が表示されます。
検索クエリ詳細には、関係知識の適用によって拡張した検索クエリを表示します。
関係拡張結果には、検索クエリに追加された語と検索語との関係を表にして示します。
検索結果に表示される内容を下図に示します。検索対象文書のタイトルがアンカーテキストとなり、クリックすると検索対象文書のURL項目に指定されたページを別ウィンドウ(または別タブ)に表示します。リンクを複数指定した場合は、タイトルと「保存文書」リンクの間に並んで設置されます。「保存文書」リンクをクリックすると、Solrに保存されたデータをもとにHTMLファイルを作成し、別ウィンドウ(または別タブ)に表示します。なお、Solrに保存されたデータとは、具体的にはタイトル、内容、キーワード、説明文を指します(キーワードと説明文は、検索対象文書が大規模文書用形式の場合のみ)。
また、検索結果画面には「CSV出力ボタン」を備えており、押下するとCSV形式で結果をダウンロードできます。CSVファイルに出力される項目は次のとおりです。
- 【検索語】
- 【検索クエリ詳細】
- 【URL|スコア|HITした語】

URLを複数指定した文書は次のように表示されます。下図は検索対象文書サンプルの例です。

検索対象文書には下図のように記載しています。

タイトル(「支払方法について」)のリンクは、属性値がsiteurlであるfield要素の値になります。
属性値がanchor1であるfield要素の値(「代金引換」)のリンクは、属性値がsiteurl1であるfield要素の値になります。
以下同様に、属性値がanchor2であるfield要素の値(「クレジットカード払い」)のリンクは、属性値がsiteurl2であるfield要素の値になり、属性値がsiteurl3であるfield要素の値(「ギフト券」)のリンクは、属性値がsiteurl3であるfield要素の値になります。
本システムの検索の流れは次のとおりです。
- ユーザが検索式を入力する。
- システムが入力された検索式の拡張を行なう。
- システムは拡張された検索式で検索実行する。
以下、検索の流れから検索式、検索式の拡張、検索実行を詳しく説明します。
- 検索式
本システムが受け付ける検索式を以下に示します。
| 構文要素 |
検索式の例 |
説明 |
| 単語 |
カード払い |
入力された単語で検索 |
論理演算子
AND, OR, NOT |
(カード払い OR クレジット払い) AND (手数料 OR リボ) NOT お勧め |
論理演算子と括弧による検索式の組み立てが可能 |
| 複数単語 |
カード払い クレジット払い |
複数単語でAND検索。AND演算子が省略されたものとみなされる |
| フレーズ(連続) |
"代金 引換料" |
複数の単語の連続出現 |
| フレーズ(近傍) |
"クレジットカード 払い"~5 |
複数の単語の近傍出現。単語間に指定した数未満の単語しか介在し得ないことを示す |
- 検索式の拡張
入力された検索式の知識(異表記辞書、関係辞書)を利用した単語およびフレーズの拡張について説明します。なお、NOT論理式内では、単語およびフレーズの拡張は行いません。
- 単語の拡張
-
検索式中の各単語と関連する単語が異表記辞書および関係辞書から引かれ、検索式に加えられます。また異表記辞書、関係辞書を基に各単語の重みが計算されます。
・検索式は、元の単語と関連する単語を加えたOR式になります。
・各単語には重みが付けられます。重みとは、検索式の ^
の後の数値を指します。省略された場合の値は1.0になります。重みは1.0をベースとし、その単語を得るために適用された異表記辞書・関係辞書に記載されたスコアと重みを掛け合わせて得られます(辞書に記載されたスコアについては、辞書(異表記、関係)を、重みについては辞書の設定についてを参照)。
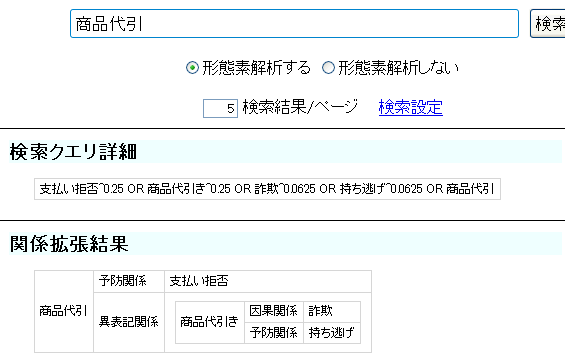
具体例として、パッケージ付属の辞書サンプル、および、同付属のプロパティファイル中に記載された辞書の設定を使い、「商品代引」とクエリを入力した場合を挙げます。
「商品代引」とクエリを入力すると、下図のように、
「支払い拒否^0.25 OR 商品代引き^0.25 OR 詐欺^0.0625 OR 持ち逃げ^0.0625 OR 商品代引」
と拡張されます。
ここで、「詐欺」の重み 0.0625 は、以下の値の積として得られます。
- 「商品代引」→「商品代引き」の異表記スコア 0.5
- 異表記重み 0.5
- 「商品代引き」→「詐欺」の因果関係でのスコア 0.5
- 因果関係の順方向重み 0.5
- フレーズの拡張
-
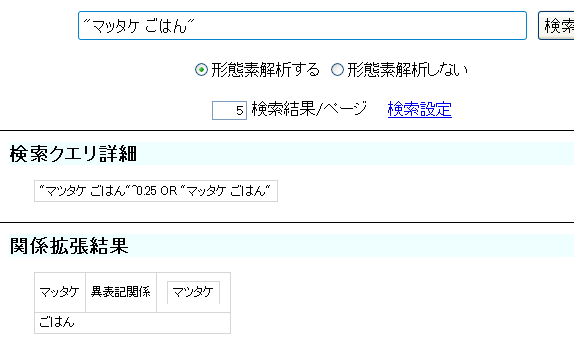
フレーズの拡張には異表記辞書を使用し、関係辞書は使用しません。フレーズの重みはフレーズ中の各単語の重みの積となります。
例えば、パッケージ付属の辞書サンプル、および、同付属のプロパティファイルの辞書の設定を使い、"マッタケ ごはん"
とクエリを入力すると、下図のように、
"マツタケ ごはん"^0.25 OR "マッタケ ごはん"
と拡張されます。
ここで、"マツタケ ごはん"
の重みは、0.25です。この値は、以下の値の積として得られます。
- 「マツタケ」→「マッタケ」の異表記スコア 0.5
- 異表記重み 0.5
- 「ごはん」の重み 1.0
- 検索実行
システムの検索処理について説明します。
検索式は、検索対象文書中のタイトルと内容の文字列に対して照合されます。また検索画面で「形態素解析する」と「形態素解析しない」を選択することができます。「形態素解析する」場合は、形態素解析によるインデックスを使って検索を行います。「形態素解析しない」場合は、文字バイグラムによるインデックスを使って検索を行います。
QE4Solrのスコアリングは、Solrのデフォルトの機能をそのまま用いて行なっています。詳細は、スコアリングを行なうSimilarity
クラスの説明をご覧ください(こちら)。
なお、コマンドライン上から全文検索システムを操作する場合は、パッケージ同梱のコマンドラインツール(QE4Scommand)をお使いください。使い方など詳細はQE4Scommandディレクトリ下のREADMEをご覧ください。
Solrには、複数ノード(Solr)にインデックスを分散配置し、各ノードのインデックスを横断的に検索する機能があります。本システムは、この機能を用いた分散検索が可能です。以下、分散検索を実施する場合の具体的な方法を説明します。
インデックスの作成
各ノードにパッケージのダウンロード、実行に必要なツール、本システムのインストールを行ない、インデックスの作成を実施します。このとき、インデックス作成制御プログラムの実行を各ノードで行う必要はありません。1台のインデックス作成制御プログラムを実行することで各ノードのインデックス作成処理を一斉に開始できます。つまり、A、B、Cの3サーバでインデックス作成を行なう場合、Aに設置したインデックス作成制御プログラムを実行することで、A、B、Cサーバのインデックス作成処理を一斉に開始できます。
そのためには、以下の設定を行う必要があります。
-
インデックス作成処理を行なう全てのマシンにパッケージをダウンロードし、実行に必要なツールや本システムのインストールを行ない、検索の事前準備の「1.インデックスの作成 2.プロパティファイルの設置」までを済ませます。さらに、インデックス作成制御プログラムを起動するサーバとHTTP通信を可能にしておきます。
-
インデックス作成制御プログラムが読み込むプロパティファイルの「ServerURLs」項目に、各ノードのホスト名:ポート番号を半角カンマ区切りで記載します。
なお、インデックス作成制御プログラムは、検索対象文書を各ノードに配布する機能も備えています。例えばA、B、Cの3サーバにインデックスを置きたいが検索対象文書はAサーバにまとまっている場合、Aサーバでインデックス作成制御プログラムを起動することで、Aサーバにある検索対象文書をB、Cサーバに分配し、インデックス作成処理を開始することが可能です。検索対象文書の配布を行なう場合、インデックス作成制御プログラムが読み込むプロパティファイルに次の設定を行ってください。
- 「DataDistribution」項目をONにする
- 「SEARCH_TARGET_DATA」項目に配布する検索対象文書が格納されたディレクトリを指定する
インデックス作成制御プログラムから配布された検索対象文書は、各ノードのプロパティファイルの「SEARCH_TARGET_DATA」項目に指定されたディレクトリに保存されます。
検索システムの起動
プロパティファイルの「SearchURLs」項目にSolrサーバのホスト名:ポート番号を半角カンマ区切りで指定します。
大規模文書用形式
【ウェブ標準フォーマット】
本システムは大規模文書用形式として、ウェブ標準フォーマットを受け付けます。ウェブ標準フォーマットとは、下に示したDTDで定義されるフォーマットを指します。
<!ELEMENT StandardFormat (Header,Text+)>
<!ATTLIST StandardFormat
OriginalEncoding CDATA #REQUIRED
Time CDATA #REQUIRED
Url CDATA #REQUIRED>
<!ELEMENT Header (Title?,InLinks?,OutLinks?)>
<!ELEMENT Title (RawString,Annotation?)>
<!ELEMENT Keywords (RawString,Annotation?)
<!ELEMENT Description (RawString,Annotation?)
<!ELEMENT InLinks (InLink+)>
<!ELEMENT InLink (RawString,Annotation?,DocID+)>
<!ELEMENT OutLinks (OutLink+)>
<!ELEMENT OutLink (RawString,Annotation?,DocID+)>
<!ELEMENT DocID (#PCDATA)>
<!ELEMENT Text (S+)>
<!ATTLIST Text
Author CDATA #IMPLIED
Date CDATA #IMPLIED
Title CDATA #IMPLIED
Type (default|blog|comment) "default">
<!ELEMENT S (RawString,Annotation?)>
<!ATTLIST S
Id CDATA #REQUIRED
Length CDATA #REQUIRED
Offset CDATA #REQUIRED>
<!ELEMENT RawString (#PCDATA)>
<!ELEMENT Annotation (#PCDATA)>
<!ATTLIST Annotation
Scheme CDATA #REQUIRED>
ウェブ標準フォーマットに明示されている情報は次のとおりです。
| タグ名 |
内容 |
| StandardFormat |
標準フォーマットのルートタグ
属性: Url: 元となるウェブページのURL
OriginalEncoding:
元となるウェブページの文字コード
Time:
ページが取得された日時(「yyyy-mm-dd hh:mm:ss」形式)
子要素: Header,Text
|
| Header |
ヘッダー要素を表すタグ
属性: なし
子要素: Title,InLinks,OutLinks |
| Title |
元となるページのタイトルを表すタグ.
属性: Offset: ファイル先頭からのオフセット
Length:
タイトルの長さ(バイト長)
Id:
文ID
子要素: RawString,Annotation |
| Keywords |
元となるページのKeywordsを表すタグ.
属性: Offset:
Length:
キーワードの長さ(バイト長)
is_Japanese_Sentence:
子要素: RawString,Annotation |
| Description |
元となるページのDescriptionを表すタグ.
属性: Offset:
Length:
Descriptionの長さ(バイト長)
is_Japanese_Sentence:
子要素: RawString,Annotation |
| InLinks |
元となるページへのインリンクの集合を表すタグ.
属性: なし
子要素: InLink |
| InLink |
元となるページへのインリンクを表すタグ.
属性: なし
子要素: RawString,Annotation,DocIDs |
| OutLinks |
元となるページからのアウトリンクの集合を表すタグ.
属性: なし
子要素: OutLink |
| OutLink |
元となるページからのアウトリンクを表すタグ.
属性: なし
子要素: RawString,Annotation,DocIDs |
| DocIDs |
文書ID の集合を表すタグ.
属性: なし
子要素: DocID |
| DocID |
文書ID を表すタグ.
属性: なし
子要素: 文書ID を表す数字列 |
| Text |
元となるページの本文の内容を表すタグ.
属性: Type: ウェブページのタイプ(通常のページ,ブログのエントリなど)
子要素: S |
| S |
ページに含まれる一文を表すタグ.
属性: Offset: ファイル先頭からのオフセット
Length:
タイトルの長さ(バイト長)
Id:
文ID
子要素: RawString,Annotation |
| RawString |
一文として抽出された文字列を表すタグ.
属性: なし
子要素: 一文として抽出された文字列 |
| Annotation |
一文として抽出された文字列の解析結果を表すタグ.
属性: Scheme: 解析に用いたツール名(e.x., Juman,Knp など)
子要素: ツールの解析結果 |
ウェブ標準フォーマットに明示されている情報のうち、本システムのXMLファイルフォーマットの必須項目に相当するものは次のとおりです。
タイトル・・・Titleタグの子要素であるRawStringの値
内容・・・Textタグの子要素であるSタグの子要素RawStringの値
URL・・・StandardFormatタグのUrl属性の値
また、検索対象文書がウェブ標準フォーマットである場合、次のデータを保存文書に含みます。
キーワード・・・Keywordsタグの子要素RawStringの値
説明文・・・Descriptionタグの子要素RawStringの値
大規模文書用形式のファイルはgzip形式で圧縮し、zipファイルにまとめて格納します。
ウェブ標準フォーマットの文書を検索対象文書として用いる場合は、プロパティファイルの「Solr_Format」項目をNOにしてください。
本ソフトウェアはフリーソフトウェアですが、著作権は、国立研究開発法人 情報通信研究機構に帰属します。本ソフトウェアは、BSDライセンス (Modified BSDLicense)、LGPL (GNU Lesser General Public License)、または、GPL (GNU General Public License) に従って使用、改変、再配布することができます。
情報分析研究室(2011年度より言語基盤グループから改称)
国立研究開発法人 情報通信研究機構
Copyright © National Institute of Information and Communications Technology (NICT). All Rights Reserved.