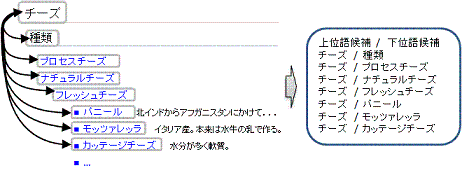
(例) 下記のWikipediaの記事の階層構造からは,"チーズ / プロセスチーズ"や"チーズ / パニール"などが上位下位関係候補として抽出されます.(他にも,"ナチュラルチーズ / フレッシュチーズ","フレッシュチーズ / パニール"などの候補も抽出されます.)
(例) 下記の記事の定義文からは,"食品 / チーズ"が上位下位関係候補として抽出されます.

(例) 下記の記事のcategoryからは,"発酵食品 / チーズ"が上位下位関係候補として抽出されます.

(上位下位関係の抽出例) 上位語 下位語 仏像 七面大明神像 ジャズフェスティバル BAY_SIDE_JAZZ_CHIBA 楽器 カンテレ 文房具 スティックのり 神楽団体 川平神楽社中 プログラミング言語 prolog 戦争映画 ハワイ・ミッドウェイ大海空戦 AOCワイン ラ・グランド・リュー ブルゴーニュ ゲーム ファイナルファンタジーXI 研究所 情報通信研究機構 (Version 1.0より出力が可能になったより詳細な上位下位関係の抽出処理の結果例) 上位語 下位語 志摩市のスポーツイベント 志摩市ロードパーティ シアトル・マリナーズの選手 エドガー・マルティネス さまぁ〜ずのレギュラー番組 リンカーン ドバイワールドカップのステップレース サンタアニタハンデキャップ オープンカーの車種 ロータス・エリーゼ トルコの都市 アンカラ上位下位関係となる用語ペアの抽出処理では,Wikipediaのページから以下の3種類を情報源として上位下位関係候補を抽出し,各候補が上位下位関係であるか否かを統計的に判定しています.
# 解凍 > tar zxvf ex-hyponymy-1.0.tar.gzインストール
> tar zxfv mecab-ipadic-2.7.0-xxxx > ./configure --with-charset=utf8 > make
> wget http://www.tkl.iis.u-tokyo.ac.jp/~ynaga/pecco/pecco.tar.bz2 > tar jxvf pecco.tar.bz2 > cd pecco > vi pecco_conf.h (pecco_conf.hの編集) > vi makefile.pecco (makefile.peccoの編集。32bitのPCの場合は、コンパイルオプション追加) > make -f makefile.pecco
(変更例) CC = ccache g++ → CC = g++ CFLAGS = -O2 -m64 -march=core2 -DNDEBUG → CFLAGS = -O2
解凍したディレクトリscript内にある,コマンド(ex_hyponymy.sh)により実行.
> script/ex_hyponymy.sh [オプション] Wikipediaファイル # jawiki-20100624-pages-meta-current.xml.bz2から全ての情報源(hierarchy, definition,category)を利用して上位下位関係候補を抽出するコマンド例 > script/ex_hyponymy.sh jawiki-20100624-pages-meta-current.xml.bz2
# 中規模な学習データにより作成したモデルファイル(data2)を使用 # 出力結果は,dataを利用した結果に比べて約10%増. > script/ex_hyponymy.sh -t ./data2 jawiki-*-pages-meta-current.xml.bz2 # 大規模な学習データにより作成したモデルファイル(data3)を使用 # 出力結果は,dataを利用した結果に比べて約20%程度増. > script/ex_hyponymy.sh -t ./data3 jawiki-*-pages-meta-current.xml.bz2
# 出力フォーマット(res_*_withWD_posWD) 上位語 下位語 評価スコア(peccoまたはTinySVMの出力値) (例) 作品 ミッドウェイ 1.13208 # 出力フォーマット(res_hier_withWD_posWD_expand) 上位語 中間語1 中間語2 下位語 (例)作品 [アメリカ合衆国の映画監督,ミネソタ州の人物]の作品 ジャック・スマイトの作品 ミッドウェイ_Midway 「中間語1」は上位語に対する下位語,中間語2と下位語に対する上位語です. 「中間語2」は上位語と中間語1に対する下位語,下位語に対する上位語です. 「中間語1」,「中間語2」は,抽出できているもののみ出力されます. ※ この例の「中間語1」では,「アメリカ合衆国の映画監督の作品」「ミネソタ州の人物の作品」の 2つが抽出されています.評価スコアは,抽出した上位下位関係の信頼度の指標となります(値が大きいほど高信頼度). 本ツールでは,我々が所有する実験用データを利用して,評価スコアが大きいものから順に精度がおおよそ90.0%となるところまで抽出しています. 例えば,後述する実験では,このスコアが0.49以上の値を持つ上位下位関係が抽出されています. さらに高精度な出力が必要な場合は,このスコアの値がさらに大きいもののみを抽出して下さい. -aオプションを使用すると,実験用データによる精度が93.0%以上となるスコアを持つ上位下位ペアが抽出されます.
プログラム実行時には,次のオプションが指定可能です.
| オプション | 説明 |
|---|---|
| -h | ヘルプメッセージを表示 |
| -d [ディレクトリ名] | mecab辞書ディレクトリ指定 |
| -t [ディレクトリ名] | 機械学習用モデルファイルのディレクトリ指定(デフォルトは./data) |
| -w [ディレクトリ名] | 中間出力ディレクトリ指定 (デフォルトはカレントディレクトリ) |
| -o [ディレクトリ名] | 最終出力ディレクトリ指定 (デフォルトはカレントディレクトリ) |
| -p | 中間ファイルを削除しない(preserve) |
| -H | hierarchy実行 |
| -D | definition実行 |
| -C | category実行 |
| -s | 省メモリモード メモリが5GB未満の場合は,省メモリモードを指定ください. (v0.82で追加) |
| -E | hierarchy処理結果の拡張を実行 hierarchy,definition,categoryの処理結果が必要です. (v1.0で追加) |
| -v | 分類器としてTiny SVMを使用 オプションを指定しない場合はpeccoを使用します. (v1.0で追加) |
| -a | 実験用データの抽出精度が93.0%となる評価スコアのしきい値を利用. 指定しない場合は,実験データの抽出精度が90.0%となる値に設定されています. (v1.0で追加) |
(-H, -D, -C ,-E いずれも指定されなければ,全て実行)
| ディレクトリ | 説明 |
|---|---|
| script/ | プログラム |
| data/ | モデルファイル用ディレクトリ:小規模な学習データから作成したhierarchy用モデルファイルが保存(処理時間が短いモデルファイル) |
| data2/ | モデルファイル用ディレクトリ:中規模な学習データから生成したhierarchy用モデルファイルが保存.処理時間は増大するが,出力結果は少し増える.peccoの使用推奨. |
| data3/ | モデルファイル用ディレクトリ:大規模の学習データから生成したhierarchy用モデルファイルが保存.処理結果数は最も多い.peccoの使用必須.(v1.0で追加) |
| data_cat/ | モデルファイル用ディレクトリ:category用のモデルファイル保存.(v1.0で追加) |
| data_def/ | モデルファイル用ディレクトリ:definition用のモデルファイル保存.(v1.0で追加) |
# 3種類の上位下位関係候補抽出処理をipadic辞書を指定して実行 # 既にEUC版のIPA辞書によりmecabを利用している場合は,UTF8でIPA辞書をインストールし,-dオプションによりIPA辞書を指定. > script/ex_hyponymy.sh -d /usr/local/mecab-0.97/lib/mecab/dic/ipadic jawiki-*-pages-meta-current.xml.bz2 # Category情報のみを利用して上位下位関係の候補を抽出 > script/ex_hyponymy.sh -C jawiki-*-pages-meta-current.xml.bz2 # 新たに追加されたモデルファイル(data3)を利用して解析. hierarchyの処理結果を拡張. > script/ex_hyponymy.sh -E -t ./data3 jawiki-*-pages-meta-current.xml.bz2
| モデルファイル | SVM | pecco |
| data(小規模な学習データにより作成) | 2,736分 | 2,371分 |
| data2(中規模な学習データにより作成) | 3,461分 | 2,396分 |
| data3(大規模な学習データにより作成) | 10,000分以上 | 2,408分 |